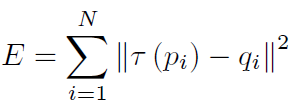Before the code, I'd like to start with an overview of process pipeline for Kinect Fustion. Here is a image from MS website (link):
 |
| Figure 1 Process pipeline for Kinect Fusion |
In order to make use of the Kinect Fusion api, we need to include NuiKinectFusionApi.h and also link the project to KinectFusion170_32.lib. The files are located in ${Kinect_SDK DIR}/Developer Toolkit v1.7.0/inc/ and ${Kinect_SDK DIR}/Developer Toolkit v1.7.0/Lib/x86/ correspondingly.
I wrote a depthSensor class to manipulate the process more easily. Firstly, declaration of the class is:
class depthSensor
{
private:
static const int WIDTH = 640;
static const int HEIGHT = 480;
static const int UPDATE_WEIGHT = 10;
int trackingErrorCount;
INuiSensor* mNuiSensor;
// -- 3D volume of reconstruction
INuiFusionReconstruction* m_pVolume;
NUI_FUSION_IMAGE_FRAME* m_pDepthFloatImage;
NUI_FUSION_IMAGE_FRAME* m_pPointCloud;
NUI_FUSION_IMAGE_FRAME* m_pShadedSurface;
HANDLE mNextDepthFrameEvent;
HANDLE mNextColorFrameEvent;
HANDLE mDepthStreamHandle;
HANDLE mColorStreamHandle;
void initKinectFusion();
void createInstance(int const kinect_index);
public:
depthSensor();
void init(int const kinect_index);
void processDepth(cv::Mat& mat);
void processKinectFusion(const NUI_DEPTH_IMAGE_PIXEL* depthPixel, int depthPixelSize, cv::Mat& mat);
const Matrix4& IdentityMatrix();
~depthSensor();
};
The most important member of the class is:// -- 3D volume of reconstruction INuiFusionReconstruction* m_pVolume;It is the 3D volumetric integration of the scene cumulatively reconstructed by new depth data from Kinect as shown in the Figure 1.
These two member function initialise Kinect instance and setup basic status:
void createInstance(int const kinect_index); void init(int const kinect_index);At the end of the init() function, we call the initKinectFusion() which initialse the parameters and status relative to Kinect Fusion algorithm. Here is the definition of initKinectFusion():
void depthSensor::initKinectFusion()
{
HRESULT hr = S_OK;
NUI_FUSION_RECONSTRUCTION_PARAMETERS reconstructionParams;
reconstructionParams.voxelsPerMeter = 256; // 1000mm / 256vpm = ~3.9mm/voxel
reconstructionParams.voxelCountX = 512; // 512 / 256vpm = 2m wide reconstruction
reconstructionParams.voxelCountY = 384; // Memory = 512*384*512 * 4bytes per voxel
reconstructionParams.voxelCountZ = 512; // Require 512MB GPU memory
hr = NuiFusionCreateReconstruction(&reconstructionParams,
NUI_FUSION_RECONSTRUCTION_PROCESSOR_TYPE_CPU,
-1, &IdentityMatrix(), &m_pVolume);
if (FAILED(hr))
throw std::runtime_error("NuiFusionCreateReconstruction failed.");
// DepthFloatImage
hr = NuiFusionCreateImageFrame(NUI_FUSION_IMAGE_TYPE_FLOAT, WIDTH, HEIGHT, nullptr, &m_pDepthFloatImage);
if (FAILED(hr))
throw std::runtime_error("NuiFusionCreateImageFrame failed (Float).");
// PointCloud
hr = NuiFusionCreateImageFrame(NUI_FUSION_IMAGE_TYPE_POINT_CLOUD, WIDTH, HEIGHT, nullptr, &m_pPointCloud);
if (FAILED(hr))
throw std::runtime_error("NuiFusionCreateImageFrame failed (PointCloud).");
// ShadedSurface
hr = NuiFusionCreateImageFrame(NUI_FUSION_IMAGE_TYPE_COLOR, WIDTH, HEIGHT, nullptr, &m_pShadedSurface);
if (FAILED(hr))
throw std::runtime_error("NuiFusionCreateImageFrame failed (Color).");
m_pVolume->ResetReconstruction( &IdentityMatrix(), nullptr);
}
Within the function, we need to setup the volume's parameters, like the size and resolution. Depends on the memory available on GPU, size and number of voxel can be set for higher or lower spacial resolution. There are three kind of data will be produced through the Kinect Fusion process. The depth float image contains the depth data from the Kinect in float format. From the depth data, we can create point cloud data. The shaded surface image shows ray-casting shaded surface of the volume at current camera position. The following codes show the process from depth image to volume reconstruction and ray-casting image for visualisation.void depthSensor::processKinectFusion( const NUI_DEPTH_IMAGE_PIXEL* depthPixel, int depthPixelSize, cv::Mat& mat )
{
// Depth pixel (mm) to float depth (m)
HRESULT hr = NuiFusionDepthToDepthFloatFrame( depthPixel, WIDTH, HEIGHT, m_pDepthFloatImage,
NUI_FUSION_DEFAULT_MINIMUM_DEPTH, NUI_FUSION_DEFAULT_MAXIMUM_DEPTH, TRUE );
if (FAILED(hr)) {
throw std::runtime_error( "::NuiFusionDepthToDepthFloatFrame failed." );
}
// Update volume based on new depth frame
Matrix4 worldToCameraTransform;
m_pVolume->GetCurrentWorldToCameraTransform( &worldToCameraTransform );
hr = m_pVolume->IntegrateFrame(m_pDepthFloatImage, UPDATE_WEIGHT, &worldToCameraTransform);
hr = m_pVolume->ProcessFrame( m_pDepthFloatImage, NUI_FUSION_DEFAULT_ALIGN_ITERATION_COUNT,
UPDATE_WEIGHT, &worldToCameraTransform );
if (FAILED(hr)) {
// If tracking is failed, count it
// Reconstruction will be reset it enough number of failed has achieved
++trackingErrorCount;
if ( trackingErrorCount >= 100 ) {
trackingErrorCount = 0;
m_pVolume->ResetReconstruction( &IdentityMatrix(), nullptr );
}
return;
}
// Get PointCloud from the volume
hr = m_pVolume->CalculatePointCloud( m_pPointCloud, &worldToCameraTransform );
if (FAILED(hr)) {
throw std::runtime_error( "CalculatePointCloud failed." );
}
// Ray-casting shaded PointCloud based on current camera pose
hr = ::NuiFusionShadePointCloud( m_pPointCloud, &worldToCameraTransform,
nullptr, m_pShadedSurface, nullptr );
if (FAILED(hr)) {
throw std::runtime_error( "::NuiFusionShadePointCloud failed." );
}
// Get 2D frame to be shown
INuiFrameTexture * pShadedImageTexture = m_pShadedSurface->pFrameTexture;
NUI_LOCKED_RECT ShadedLockedRect;
hr = pShadedImageTexture->LockRect(0, &ShadedLockedRect, nullptr, 0);
if (FAILED(hr)) {
throw std::runtime_error( "LockRect failed." );
}
mat = cv::Mat( HEIGHT, WIDTH, CV_8UC4, ShadedLockedRect.pBits );
// We're done with the texture so unlock it
pShadedImageTexture->UnlockRect(0);
}
At each frame, the camera pose is tracked so that new point cloud can be integrated into current volume correctly. If the camera is static, then we don't need to track camera position and the transformation matrix is set to identity.Full code download: depthSensor.cpp; depthSensor.h